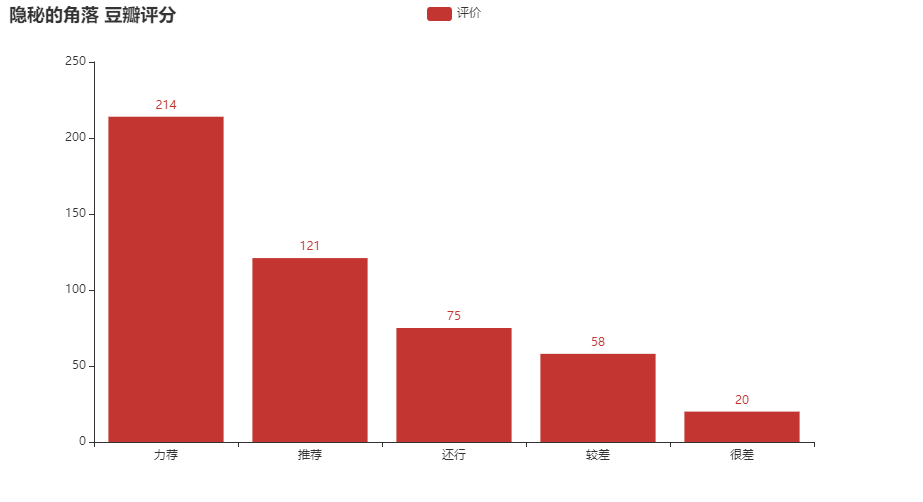
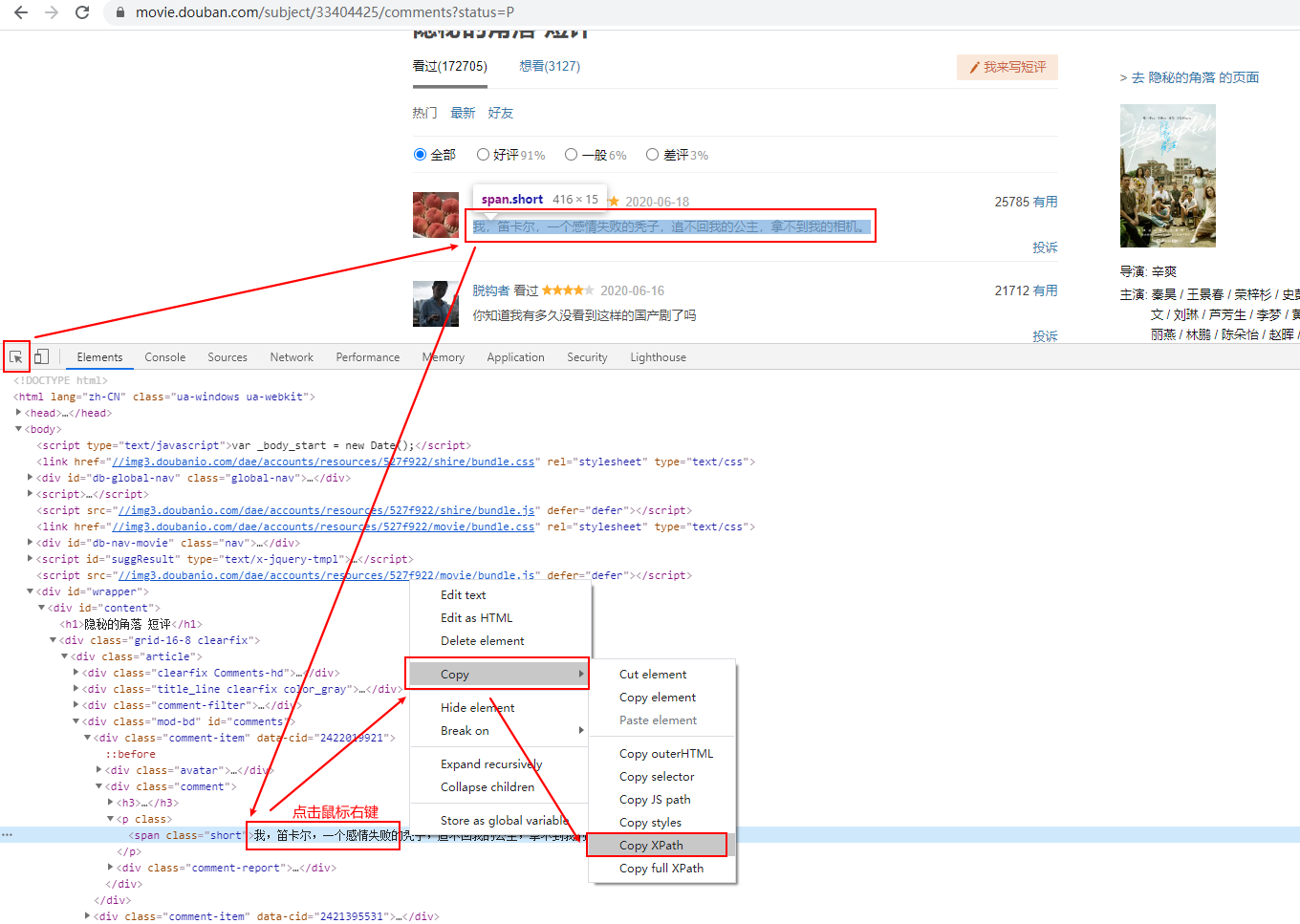
本文主要对当前热门剧《隐秘的角落》进行豆瓣短评以及评价进行可视化分析,数据抓取主要为python编写的爬虫。
本文主要分为2个部分,分别对爬虫和可视化部分进行详解,本文脚本基于python 3.8.0版本进行编写
| 第三方依赖包 |
说明 |
| pyecharts |
百度开源可视化工具,用于生成图表和词云 |
| jieba |
国内比较好用的分词工具 |
| requests |
python常用HTTP 库 |
| lxml |
pyhon常用XML和HTML解析库 |

数据抓取
日志打印
为了方便调试和问题定位,单独引入了logging模块进行日志打印,为方便复用,日志部分单独写到了一个文件中,创建log.py文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
import logging
import logging.handlers
class Logger(object):
level_relations = {
'debug':logging.DEBUG,
'info':logging.INFO,
'warning':logging.WARNING,
'error':logging.ERROR,
'crit':logging.CRITICAL
}#日志级别关系映射
def __init__(self,filename,level='info',when='H',backCount=3,fmt='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'):
#日志格式
#----------------------------
# %(asctime)s 年-月-日 时-分-秒,毫秒
# %(filename)s 文件名,不含目录
# %(pathname)s 目录名,完整路径
# %(funcName)s 函数名
# %(levelname)s 级别名
# %(lineno)d 行号
# %(module)s 模块名
# %(message)s 日志信息
# %(name)s 日志模块名
# %(process)d 进程id
# %(processName)s 进程名
# %(thread)d 线程id
# %(threadName)s 线程名
self.logger = logging.getLogger(filename)
format_str = logging.Formatter(fmt)#设置日志格式
self.logger.setLevel(self.level_relations.get(level))#设置日志级别
sh = logging.StreamHandler()#往屏幕上输出
sh.setFormatter(format_str) #设置屏幕上显示的格式
th = logging.handlers.TimedRotatingFileHandler(filename=filename,when=when,backupCount=backCount,encoding='utf-8')#往文件里写入#指定间隔时间自动生成文件的处理器
#实例化TimedRotatingFileHandler
#interval是时间间隔,backupCount是备份文件的个数,如果超过这个个数,就会自动删除,when是间隔的时间单位,单位有以下几种:
# S 秒
# M 分
# H 小时、
# D 天、
# W 每星期(interval==0时代表星期一)
# midnight 每天凌晨
th.setFormatter(format_str)#设置文件里写入的格式
self.logger.addHandler(sh) #把对象加到logger里
self.logger.addHandler(th)
|
爬虫
豆瓣对未登陆账号的请求有些限制,短评只能看到前面200条,所以采取了登陆账号的方式来请求更多的数据。豆瓣返回的数据为xml,因此采用了xpath的方式来获取短评数据,然后将数据存入本地文本中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
class sprider():
def __init__(self):
# 设置请求头
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'}
self.short_comments_file = sys.path[0]+"\\Short_comments_file.txt"
self.score_file = sys.path[0]+"\\score_file.txt"
def login(self,session):
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
## 账号和密码需要修改为正确的
postData = {'ck': '',
'name': 'yourname',
'password': 'passwd',
'remember': 'false',
'ticket': ''}
# 从网上看到,需要先get请求一次才能成功,不然能登录能200,但是不能进行后续的get请求抛403,具体原因不详
a = session.get(login_url,headers=self.headers)
b = session.post(login_url, data=postData, headers=self.headers)
if b.status_code == 200:
logger.logger.info("登录成功")
else:
# 登陆失败打印返回码和失败详情
logger.logger.error("登录失败:"+str(b.status_code)+str(b.text))
sys.exit(48)
def get_request(self,url,session):
# get请求获取短评详情
request = session.get(url,headers=self.headers)
if request.status_code == 200:
# 防止乱码,将编码格式设置为utf-8
request.encode = 'utf-8'
return request.text
else:
logger.logger.error('current status_code:'+str(request.status_code)+str(request.text))
sys.exit(44)
def xpath_analysis(self, text, xpath):
html = etree.HTML(text)
# 使用xpath进行短评解析
result = html.xpath(xpath)
return result
def to_file(self, filename, data):
# 采用追加的方式将内容写入文件
with open(filename, 'a', encoding='utf-8') as f:
# xpath获取的data为列表,所以用遍历的方式写入
logger.logger.info(data)
for i in data:
f.write(i+'\n')
def init_file(self, filename):
# 初始化文件,直接清空
with open(filename, 'w') as f:
f.write('')
|
可视化
可视化部分主要是对前一步抓取到的数据进行清洗和分析,分词库用的是jieba。图表生成使用的是百度开源可视化工具pyecharts,本文只用了柱状图和词云,更多高级用法见pyecharts官方文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
class visualization():
def __init__(self):
# 初始化文件路径
self.short_comments_file = sys.path[0]+"\\Short_comments_file.txt"
self.score_file = sys.path[0]+"\\score_file.txt"
self.path = sys.path[0]
def analysis_score(self):
evaluate = {}
with open(self.score_file, 'r', encoding='utf-8') as f:
for i in f.readlines():
i = re.sub(r"[A-Za-z0-9\-\:]", "", i)
i = i.strip() # 去掉每行的换行符
# 如果这个没出现过,就初始化为1
if i not in evaluate:
evaluate[i] = 1
logger.logger.debug(evaluate)
else:
# 如果已经出现过了,就在自加1
evaluate[i] += 1
logger.logger.debug(evaluate)
logger.logger.info(evaluate)
bar = Bar()
eva = []
count = []
for k, v in evaluate.items():
if k != '':
eva.append(k)
count.append(v)
bar.add_xaxis(eva) # 柱状图x轴
logger.logger.info('xaxis'+str(eva))
bar.add_yaxis("评价", count) # 柱状图y轴
logger.logger.info('yaxis'+str(count))
bar.set_global_opts(title_opts=opts.TitleOpts(title="隐秘的角落 豆瓣评分"))
# 生成可视化图表
bar.render(self.path+"\\score.html")
def analysis_short_comment(self):
cut_words = ""
for line in open(self.short_comments_file, 'r', encoding='utf-8'):
line.strip('\n')
# 正则去掉标点等无效的字符,对数据进行清洗
line = re.sub(r"[A-Za-z0-9\:\·\—\,\。\“ \”\....]", "", line)
# cut_all=False为精确模式,cut_all=True为全词模式
seg_list = jieba.cut(line, cut_all=False)
cut_words += (" ".join(seg_list))
all_words = cut_words.split()
c = Counter()
for x in all_words:
if len(x) > 1 and x != '\r\n':
c[x] += 1
words = c.most_common(500) # 输出词频最高的前500词
logger.logger.debug(words)
wordcloud = WordCloud()
wordcloud.add("", words, word_size_range=[5, 100], shape='circle')
wordcloud.set_global_opts(title_opts=opts.TitleOpts(title="隐秘的角落 短评"))
wordcloud.render(self.path+"\\short_comment.html")
|
主函数
为了防止被豆瓣封IP,降低了采集频率采取了单线程和每次请求随机sleep 0.1s-4s的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
def run_sprider(sprider):
# 初始化文件
sprider.init_file(sprider.short_comments_file)
sprider.init_file(sprider.score_file)
# 遍历获取数据
s = requests.session()
sprider.login(s)
for page_start in range(0, 500, 20): # 范围从0-500,步长为20,页面上总评论数为500+
try:
delay = round(random.uniform(0.1, 4), 1)
logger.logger.info('i will sleep:'+str(delay)+'s')
time.sleep(delay)
URL = 'https://movie.douban.com/subject/33404425/comments?start={}&limit=20&sort=new_score&status=P'.format(
page_start)
logger.logger.info('current_request_url:'+URL)
x = sprider.get_request(URL,s)
# 短评的xpath路径
xpath = '//*[@id="comments"]/div[*]/div[2]/p/span/text()'
short_comment = sprider.xpath_analysis(x, xpath)
sprider.to_file(sprider.short_comments_file, short_comment)
# 评分的xpath路径
xpath2 = '//*[@id="comments"]/div[*]/div[2]/h3/span[2]/span[2]/@title'
score = sprider.xpath_analysis(x, xpath2)
sprider.to_file(sprider.score_file, score)
except Exception as e:
logger.logger.error(e)
logger.logger.info('current_page:'+page_start)
sys.exit(146)
if __name__ == "__main__":
# 数据抓取
sprider = sprider()
run_sprider(sprider)
# 数据分析和图标生成
c = visualization()
c.analysis_score()
c.analysis_short_comment()
|
完整源码
log.py
sprider.py